
Título original: The impact of human expert visual inspection on the discovery of strong gravitational lenses
Autores: Karina Rojas, Thomas E. Collett, Daniel Ballard, Mark R. Magee, Simon Birrer, Elizabeth Buckley-Geer, James H. H. Chan, Benjamin Clément, José M. Diego, Fabrizio Gentile, Jimena González, Rémy Joseph, Jorge Mastache, Stefan Schuldt, Crescenzo Tortora, Tomás Verdugo, Aprajita Verma, Tansu Daylan, Martin Millon, Neal Jackson, Simon Dye, Alejandra Melo, Guillaume Mahler, Ricardo L. C. Ogando, Frédéric Courbin, Alexander Fritz, Aniruddh Herle, Javier A. Acevedo Barroso, Raoul Cañameras, Claude Cornen, Birendra Dhanasingham, Karl Glazebrook, Michael N. Martinez, Dan Ryczanowski, Elodie Savary, Filipe Góis-Silva, L. Arturo Ureña-López, Matthew P. Wiesner, Joshua Wilde, Gabriel Valim Calçada, Rémi Cabanac, Yue Pan, Isaac Sierra, Giulia Despali, Micaele V. Cavalcante-Gomes, Christine Macmillan, Jacob Maresca, Aleksandra Grudskaia, Jackson H. O’Donnell, Eric Paic, Anna Niemiec, Lucia F. de la Bella, Jane Bromley, Devon M. Williams
Instituição da primeira autora: Institute of Cosmology and Gravitation, University of Portsmouth, Burnaby Rd, Portsmouth PO1 3FX, UK.
Status: Disponível em formato pré-print no ArXiv
Como você acha que seria o seu desempenho contra um computador em um jogo de “Eu Espio” astrofísico? O artigo de hoje explora a habilidade que humanos possuem para identificar lentes gravitacionais em um conjunto de aproximadamente 1500 imagens, em uma tentativa de obter uma ideia melhor do papel que humanos podem exercer em uma indústria dominada por computadores quanto à detecção de lentes.
Humanos reais, inteligência artificial
Em uma era onde termos como “inteligência artificial (IA)” e “aprendizado de máquina” são jogados constantemente em conversas diárias, pode ser difícil apreciar o quão essencial é o trabalho humano em permitir que estas tecnologias atuem como desejado. Por exemplo, a fim de treinar redes neurais artificiais, humanos frequentemente precisam atuar como “professores” destas redes, para ajudá-las a compreender quando ela sucede ou falha em uma dada tarefa. Na verdade, se você já teve que verificar sua identidade em um website ao identificar objetos em imagens, por exemplo através do serviço ReCAPTCHA do Google, você provavelmente já participou nesta atividade de treinamento sem saber.
Essa ideia de intervenção humana é extremamente relevante quando se trata de utilizar técnicas de aprendizado de máquina na astronomia e astrofísica. Levantamentos astronômicos em grande escala, munidos de telescópios modernos, nos fornecem dados e imagens de grande utilidade, confiar apenas em computadores para identificar padrões de interesse particular nestes dados pode fazer com que percamos informações que o olho humano pode capturar, ou então podem produzir detecções do tipo falso-positivo de algum objeto de interesse. Assim, nos estágios finais de uma análise, ainda é útil para seres humanos participarem da análise e checar o trabalho realizado pela IA.

A detecção de lentes gravitacionais não é exceção a este caso. Tais lentes são resultados de objetos extremamente massivos ou compactos que distorcem o espaço-tempo ao seu redor, e são uma predição crucial da Teoria da Relatividade Geral. Este efeito pode causar distorções na aparência de objetos distantes, mas tal como uma lente óptica presente num par de óculos, estas lentes gravitacionais podem focar ou até magnificar a luz destes objetos, de forma a podermos enxergá-los com maior clareza daqui da Terra. Assim, lentes gravitacionais são excelentes ferramentas para estudar objetos incrivelmente distantes – ou pouco luminosos – que de outro modo seriam invisíveis para nós, e também para estudar a matéria escura, testar modelos cosmológicos, bem como explorar várias outras questões astrofísicas.Em casos extremos, lentes gravitacionais podem esticar a aparência de objetos ao fundo em grandes arcos, um fenômeno conhecido como anéis de Einstein, bem como produzir imagens duplas. Tradicionalmente, as buscas por estas lentes foram conduzidas via inspeção humana, onde frequentemente grupos de cientistas visualmente combinam estas imagens. Agora que computadores estão tomando conta de grande parte do processo de identificação, os humanos estão atuando cada vez mais como treinadores e verificadores, uma vez que modelos computacionais ainda sofrem com altas taxas de falso-positivo devido à inerente rareza das lentes gravitacionais identificáveis. Porém, humanos tem os seus próprios vieses, e assim compreender quais imagens humanos podem ou não identificar com confiança é algo importante para entender seus efeitos no estágio final de filtragem de imagens.

ReCAPTCHA relativístico
No artigo de hoje, os autores constroem uma espécie de ReCAPTCHA relativístico: um estudo para determinar o quão bem “experts humanos” (pessoas que já tiveram algum contato com astrofísica, desde estudantes de mestrado até professores com décadas de experiência em lentes gravitacionais) poderiam identificar tais lentes em centenas de imagens. A fim de testar as suas vantagens e limitações através de uma variedade de cenários de lentes, lhes apresentaram imagens pertencentes de várias amostras de dados diferentes e também de simulações, contendo imagens com e sem lentes. Cada imagem foi apresentada em três escalas de brilho diferente (padrão, azul e raiz quadrada) para permitir o melhor delineamento de padrões sutis. Os autores esperavam que um conjunto de lentes simuladas com padrões brilhantes seriam as mais fáceis de serem identificadas por estes experts humanos, enquanto imagens de lentes obtidas por telescópios terrestres – logo, possuindo menor resolução – seriam as mais difíceis de distinguir.
A fim de quantificar quão bem cada imagem foi classificada em cada categoria, participantes foram avisados para rotular cada imagem como “certamente contendo uma lente”, “provavelmente contendo uma lente”, “provavelmente não contendo uma lente”, “improvável de conter uma lente”. Objetos que um grande número de participantes disseram que certamente contém uma lente receberam scores agregados próximos a 1, enquanto os objetos cuja maioria dos participantes disseram que não contem lentes receberam scores próximos a 0. Ao rastrear como o score médio de vários objetos se correlacionam com parâmetros tais quais magnitude, razão sinal-ruído, e se de fato tem ou não uma lente no objeto, o time de pesquisadores foi capaz de determinar onde experts humanos eram mais ou menos confiáveis em suas respostas.
Conforme mostrado na Figura 3, humanos corretamente identificaram imagens com lentes (i.e., atribuíram scores altos) quando os raios dos anéis de Einstein eram maiores do que 1.2 segundos de arco, e quando o objeto era mais brilhante do que uma magnitude astrofísica de 23 (aproximadamente 4.000 vezes menos brilhantes do que Plutão visto da Terra). Comparando experts humanos com os scores produzidos por uma rede neural convolucional treinada para identificar lentes, os pesquisadores encontraram baixa correlação, especialmente em imagens ambíguas (score humano próximo a 0.5), indicando assim que estas redes podem estar selecionando diferentes tipos de padrões nas imagens, se comparado aos humanos, para realizar esta classificação.
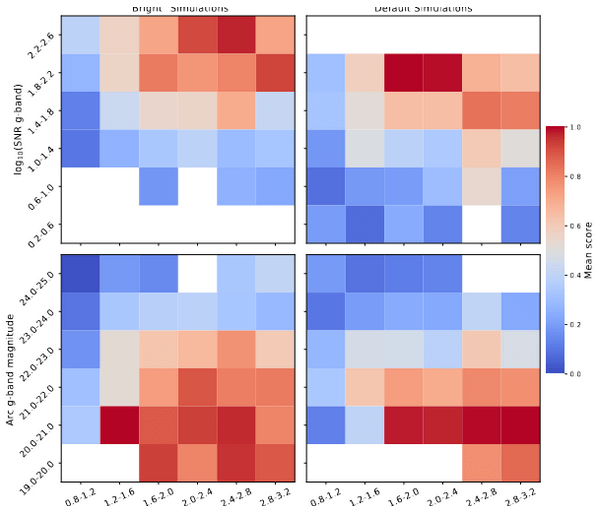
Apesar das limitações de experts humanos em detectar lentes pequenas e pouco brilhantes, os pesquisadores encontraram que a maioria dos participantes classificaram imagens corretamente. Por exemplo, 99% das imagens rotuladas como “certamente contem lentes” pelos participantes de fato contem uma lente, e 90% das imagens rotuladas “improváveis de conterem lentes” de fato não as possuíam. A maior ambiguidade ocorreu quando humanos rotularam uma imagem como “provavelmente não contem lente” – imagens rotuladas assim foram quase divididas igualmente entre imagens com e sem lentes. Talvez um resultado surpreendente seja o fato dos pesquisadores terem encontrado que a confiança dos scores não está correlacionada com a posição acadêmica, anos de experiência, ou confiança auto-reportada pelos participantes – então, se você estiver lendo isso, há uma boa chance de você ganhar de um expert neste jogo de “Eu-espião” astronômico!
Trabalho em time faz com que identificação de lentes seja trabalho dos sonhos
Mesmo que experts humanos sejam classificadores confiáveis no geral, o estudo encontrou uma variação consideravelmente alta no score entre indivíduos. Isto é especialmente problemático quando humanos se deparam com imagens ambíguas que computadores tem dificuldades em classificar. Para tornar este problema ainda pior, os pesquisadores encontraram que os participantes mudaram as suas classificações, quando deparados com imagens que já haviam classificado anteriormente. Para contabilizar alguns destes efeitos, pode ser preferível montar grupos de vários experts trabalhando na classificação em conjunto. A fim de examinar como acurácia e confiança das classificações mudam com o tamanho do grupo de humanos, os pesquisadores reduziram sua amostra, criando 200 “times virtuais” de tamanhos aleatórios e então compararam suas performances. Para reduzir o desvio padrão dos scores para menos de 0.1 nesta escala que varia de 0 a 1, eles encontraram que times de 6 ou mais usuários são necessários. Para atingir um desvio padrão abaixo de 0.05, os times devem ser compostos de 15 ou mais classificadores.
Por mais poderosos que sejam os novos telescópios e projetos de levantamentos astronômicos quanto a suas habilidades em explorar o cosmos, nossos catálogos de potenciais lentes gravitacionais provavelmente aumentarão exponencialmente em qualidade e quantidade. Mesmo com a constante melhoria do processamento de imagens na identificação de lentes, realizado por métodos computacionais, humanos ainda possuem um papel vital em confirmar a sua presença e no treinamento de modelos computacionais. E, como típico na astronomia, os melhores resultados virão provavelmente de cientistas trabalhando em grupo.
Adaptação do astrobite escrito originalmente por Lucas Brown, e editado por Mark Dodici and Graham Doskoch. Crédito da imagem de capa: Modificada por L. Brown, originalmente de Rojas et al. 2023
