
Título: “Super-resolving Dark Matter Halos using Generative Deep Learning“
Autores: David Schaurecker, Yin Li, Jeremy Tinker, Shirley Ho, and Alexandre Refregier
Instituição do primeiro autor: Institute for Particle Physics and Astrophysics, ETH Zurich, Zurich
Status: preprint no arXiv
Dados grandes, simulações caras
Não é segredo que, cosmologicamente falando, estamos vivendo em uma era de big data. Graças a incríveis levantamentos de galáxias como DESI, EUCLID, DES, and Rubin, astrônomos estão mapeando amostras cada vez maiores do nosso Universo usando galáxias cada vez mais distantes. A fim de que nossa compreensão teórica possa manter o ritmo das observações, precisamos ser capazes de comparar estes mapas com catálogos simulados dessas galáxias distantes—ou seja, precisamos de simulações maiores, com resolução mais alta. Além disso, precisamos muitas destas simulações para explorar diferentes parâmetros cosmológicos e realizar análises estatísticas. Isso é muito custoso computacionalmente!
Neste artigo, os autores apresentam uma maneira menos custosa de avançar. As questões que eles buscam respondem incluem:
1. Podemos produzir uma simulação de baixa resolução, preenchendo as lacunas com aprendizado de máquina no final?
2. Quão semelhante pode ser este procedimento comparado a produzir diretamente uma simulação de alta resolução?
Leia adiante para saber mais!
Preenchendo as lacunas com aprendizado de máquina
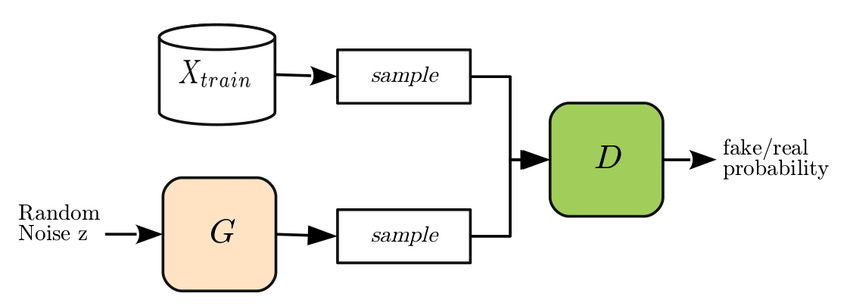
Os autores utilizam algo chamado generative adversarial network (GAN): um algoritmo de aprendizado de máquina onde duas redes neurais artificiais—chamadas de geradora e discriminadora—atuam como adversárias competindo em um jogo de soma zero. Um gráfico ilustrando como a GAN trabalha é mostrado na figura 1. A tarefa do gerador é aprender a produzir uma amostra que parece a mesma do conjunto de treino que o algoritmo recebe, enquanto a tarefa do discriminador é dizer o quanto estes dados produzidos do gerador difere da amostra real. O jogo é pesado: só termina quando o discriminador perde, ou seja, quando o gerador produz uma amostra sintética tão boa que o discriminador consistentemente relata uma probabilidade de 50%/50% da amostra ser real ou falsa. Ao passo que isso é uma notícia ruim para o discriminador, é uma notícia excelente para o usuário—significa que podemos produzir amostras falsas de maneira realista!
Comparando galáxias reais e simuladas
No caso do artigo de hoje, os autores comparam duas simulações contendo apenas matéria escura da suíte Illustris: A simulação Illustris-2-Dark, de alta resolução, e a Illustris-3-Dark, que apresenta resolução menor. Eles consideram apenas uma “fotografia” atual das simulações e dividem os seus volumes em 8 partições: 6 como conjunto de treino e 2 para validação e teste. A GAN é então treinada com uma das 6 partições da simulação de baixa resolução, a fim de criar uma versão correspondente daquela de alta resolução. Uma vez que o treino é completado, a GAN é testada com uma das 2 partições de teste/validação que o gerador não viu ainda. Os resultados encontram-se na figura 2.
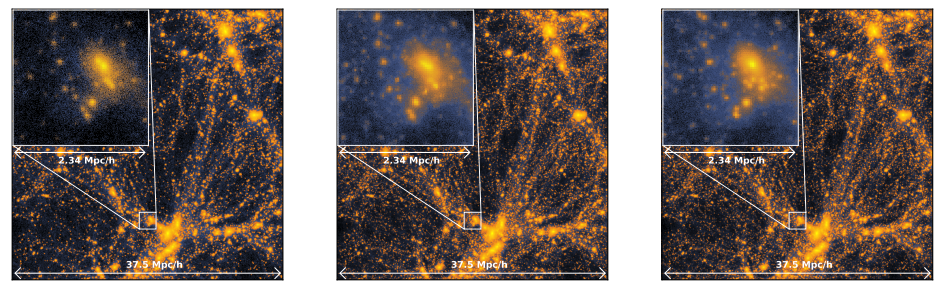
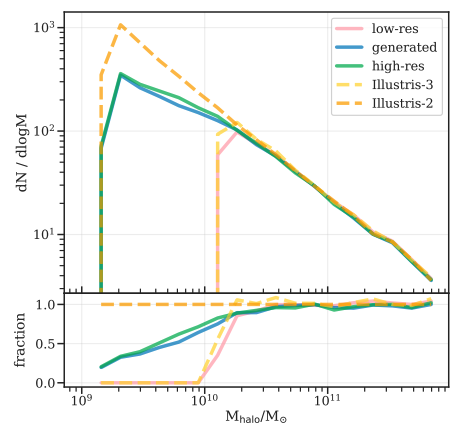
Em geral, a GAN faz um excelente trabalho—o painel central e da direita da Figura 2 são praticamente indistinguíveis a olho nu! A maior diferença entre os dados de resolução mais alta e mais baixa consiste na presença de pequenos aglomerados de matéria escura, que a GAN tem sucesso em recuperar. Contudo, note que os dados produzidos pela máquina não conferem exatamente com os da simulação de alta resolução—e nem esperamos isso! Afinal, a rede neural não pode recuperar informação perdida na simulação Illustris-3 de baixa resolução; mas pode tentar descobrir como uma simulação de alta resolução pode parecer, estatisticamente falando. Então, não esperamos que uma simulação produzida pela GAN revele a localização exata e verdadeira de uma bolha de matéria escura, porém esperamos que medidas estatísticas realizadas sobre um pedaço da simulação sejam realistas. E é isso que acontece: estas medidas estatísticas são consistentes com os dados! Por exemplo, podemos usar o espectro de potência da matéria escura ou função de massa de halo, como ilustrado na Figura 3 abaixo.
Conclusão
Mesmo que aprendizado de máquina não possa recuperar dados perdidos, uma rede neural treinadamente devidamente pode nos fornecer maior poder de resolução nas estatísticas de uma simulação. Além disso, uma vez treinada, é muito mais rápido utilizar uma GAN para extrapolar a resoluções mais altas do que produzir uma simulação de alta resolução em si. O objetivo principal seria treinar uma GAN tão bem a ponto de poder trabalhar com qualquer simulação de matéria escura. Na verdade, os autores utilizaram sua rede neural na suíte mais recente de simulações do Illustris—chamada Illustris-TNG—e encontraram que o algoritmo ainda é capaz de prever novos halos de matéria escura com sucesso! Este é um início promissor para sermos capaz de criar catálogos simulados realistas a apenas uma fração do custo computacional de uma simulação de alta resolução.
Adaptado da postagem original do astrobites “Adversarial Networks, Collaborative Cosmology“, de Luna Zagorac.
