
Título: A Gigaparsec-Scale Hydrodynamic Volume Reconstructed with Deep Learning
Autores: Cooper Jacobus, Solene Chabanier, Peter Harrington, JD Emberson, Zarija Lukić e Salman Habib
Instituição do primeiro autor: Lawrence Berkeley National Laboratory, EUA
Status: Preprint no arXiv
As simulações se tornaram uma das ferramentas indispensáveis da astrofísica moderna. Seja para tentar entender uma estrela, um disco de núcleo ativo de galáxia (AGN, do inglês active galactic nucleus), uma galáxia ou o próprio universo, provavelmente haverá uma simulação para isso. Um dos tipos mais populares de simulação na astrofísica moderna é a simulação hidrodinâmica de estruturas em grande escala (por exemplo, Illustris, Eagle, Astrid), que é desenvolvida para imitar um pedaço do universo contendo milhões de galáxias. Essas simulações começam com uma simulação de N-corpos na qual bilhões de partículas que representam a matéria escura são simuladas sob a influência atrativa da gravidade. Além da — é simulada como um tipo de ‘fluido’ navegando no mar de matéria escura — daí a parte ‘hidrodinâmica’.
Cada simulação desse tipo é um equilíbrio delicado entre três escolhas concorrentes: (i) o tamanho total da simulação; (ii) o poder computacional necessário para rodá-la; (iii) a resolução, que, em termos simples, é a combinação das menores escalas de distância e tempo na qual os dados na simulação são confiáveis ou significativos. Quando se desenvolve uma simulação, caso se queira alterar uma dessas três quantidades, você deve considerar o efeito das outras duas. Por exemplo, se você quer um grande volume de simulação, será necessário aumentar o poder computacional ou reduzir a resolução. As decisões tomadas ao projetar uma simulação se resumem aos recursos disponíveis e aos objetivos científicos da simulação, e os pesquisadores que criam e analisam simulações desenvolveram muitos métodos inteligentes (como, por exemplo, técnicas de zoom) para impulsionar o que é possível com as simulações aos seus limites computacionais.
Os autores de hoje usam aprendizado de máquina para reduzir as limitações desses três fatores concorrentes ao usar um modelo de aprendizado de máquina para substituir alguns aspectos computacionais custosos de uma simulação hidrodinâmica. Um bom processo de aprendizado de máquina requer dados de treinamento e de teste, e os autores de hoje usam o código Nyx para criar os deles. Eles criaram dois pares de simulações (quatro no total), cada um com uma caixa de 80 Mpc por lado. Para cada par, eles fizeram uma versão em alta resolução e uma em baixa resolução. Então, eles criaram um modelo de aprendizado profundo customizado e treinaram-no usando um par para recriar uma saída em alta resolução a partir da entrada em baixa resolução (veja Figura 1 para um exemplo). Em seguida, eles usaram o outro par de simulações para avaliar o desempenho do modelo na recriação da versão em alta resolução a partir da versão em baixa resolução.
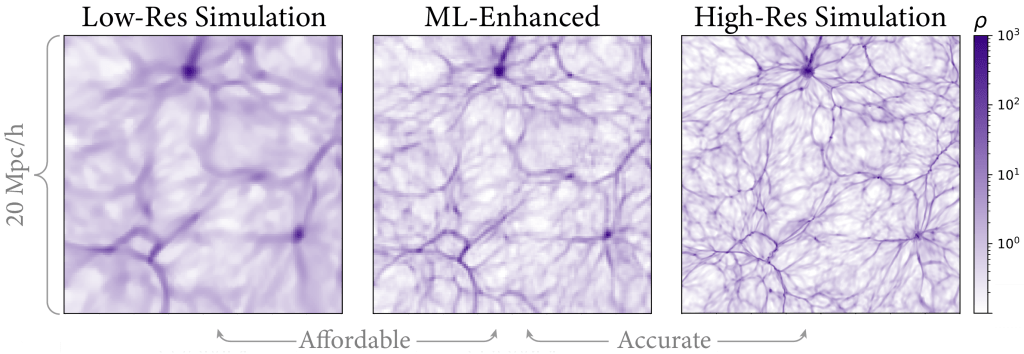
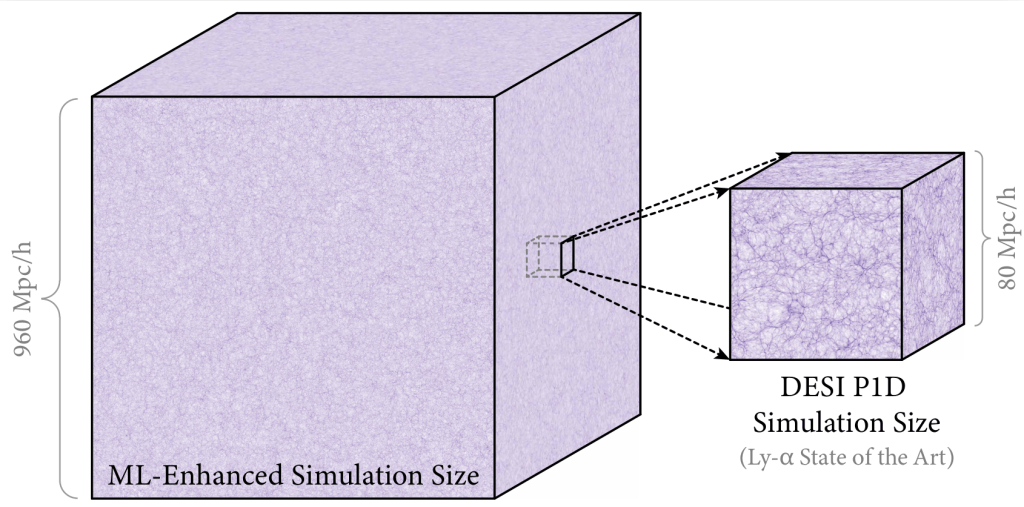
Após usar suas duas simulações para treinar e testar seu modelo, eles dão um passo além. Eles usam seu modelo em uma simulação de baixa resolução, aproximadamente 1000 vezes maior que a simulação original, quase 1 Gpc no comprimento do lado da caixa (no universo real, este vasto volume conteria dezenas a centenas de milhões de galáxias; a Figura 2 compara os volumes das simulações original e maior). Eles usam seu algortitmo treinado de aprendizado de máquina para tornar a simulação em baixa resolução em uma predição do que uma caixa em alta resolução deveria parecer. Ao fazer isso, eles essencialmente contornam a quantidade enorme de poder computacional necessário para que uma simulação desse tamanho e com essa resolução fosse realizada, enquanto retêm importantes detalhes e características da simulação em alta resolução. Por que os autores deveriam querer criar uma caixa simulada muito maior que aquela que eles já têm em tal resolução? Caixas de 80 Mpc não são grandes o suficiente?
Bem, os autores estão interessados em um caso astrofísico particular. Eles desenvolveram esse processo de simulação com aprendizado de máquina para investigar um fenômeno chamado floresta de Lyman-alpha (Lyman-alpha forest). Resumindo a história, quando a luz de fontes brilhantes distantes, como AGN, passa através do universo, duas coisas principais acontecem a essa luz em seu caminho até os nossos telescópios. Primeiro, elas passa através de gás de hidrogênio neutro e, segundo, a luz sofre um desvio para o vermelho devido à expansão do universo. Na primeira etapa, o hidrogênio absorve um comprimento de onda específico chamado de comprimento de onda de Lyman-alpha, que, então, falta no espectro que chega à Terra. Na segunda etapa, devido à expansão do Universo, aquela lacuna pode se desviar para comprimentos de onda maiores, uma vez que todo o espectro se desloca para o vermelho. O quanto ele se desvia pode nos dizer quão longe o gás está. Podemos ver vários espaços no espectro se há múltiplas nuvens de gás ao longo da linha de visada, resultando em um perfil de densidade unidimensional do gás de hidrogênio para distâncias muito longínquas. Conhecer essa densidade de hidrogênio pode nos dizer todo tipo de coisas sobre o Universo e como ele evoluiu.
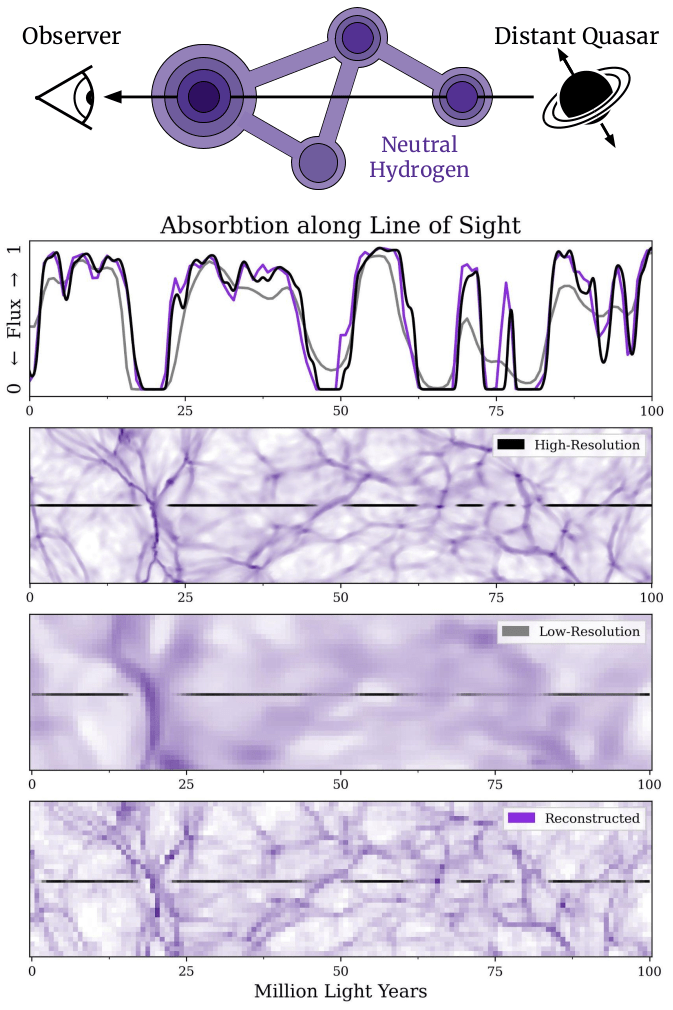
Pesquisadores, incluindo os autores, estão trabalhando em direção ao futuro próximo quando observações de Lyman-alpha construirão um mapa tridimensional dessa distribição de hidrogênio, um passo significativo em relação aos muitos mapas unidimensionais que temos atualmente. No entanto, usar simulações para modelar a floresta de Lyman-alpha e testá-las em levantamentos futuros requer uma combinação de tamanho e resolução que não é viável para simulações modernas. Então, é por isso que os autores de hoje escolhem as metas de tamanho e resolução que escolheram. Dado seu sucesso em treinar um modelo de aprendizado de máquina para recriar um grande volume em alta resolução com baixo custo computacional, uma maneira completamente nova para investigar a floresta de Lyman-alpha e a evolução do Universo como um todo está mais próxima que nunca.
Traduzido e adaptado para o português do astrobite original “Using Machine Learning to Make A Really Big Detailed Simulation“, escrito por William Smith e editado por Ivey Davis.
Créditos da imagem em destaque: William Smith (adapted from Fernandez, Bird and Ho, DOI: 10.48550/arXiv.2309.03943).
